
映画The Thinking Gameを見たのと斎藤康毅氏のゼロから作るDeep Learning6 LLM編(公開Review版)を読んで深層強化学習を知りたくなった。そこで、この本を図書館で借りてきた。
第一印象はムズい本だというものだったが、ソースコードを追う内に解ってきた。状態s、行動aは理解が容易なのだが、方策π、パラメータθが解らん。これが最初に出てきて、気になって読み進めないのだ。
しかし、コードを解読していくと著者が難しい概念を頑張って解説していると気がついた。強化学習はLLMで採用されているTransformerやSelf-Attentionよりムズい。
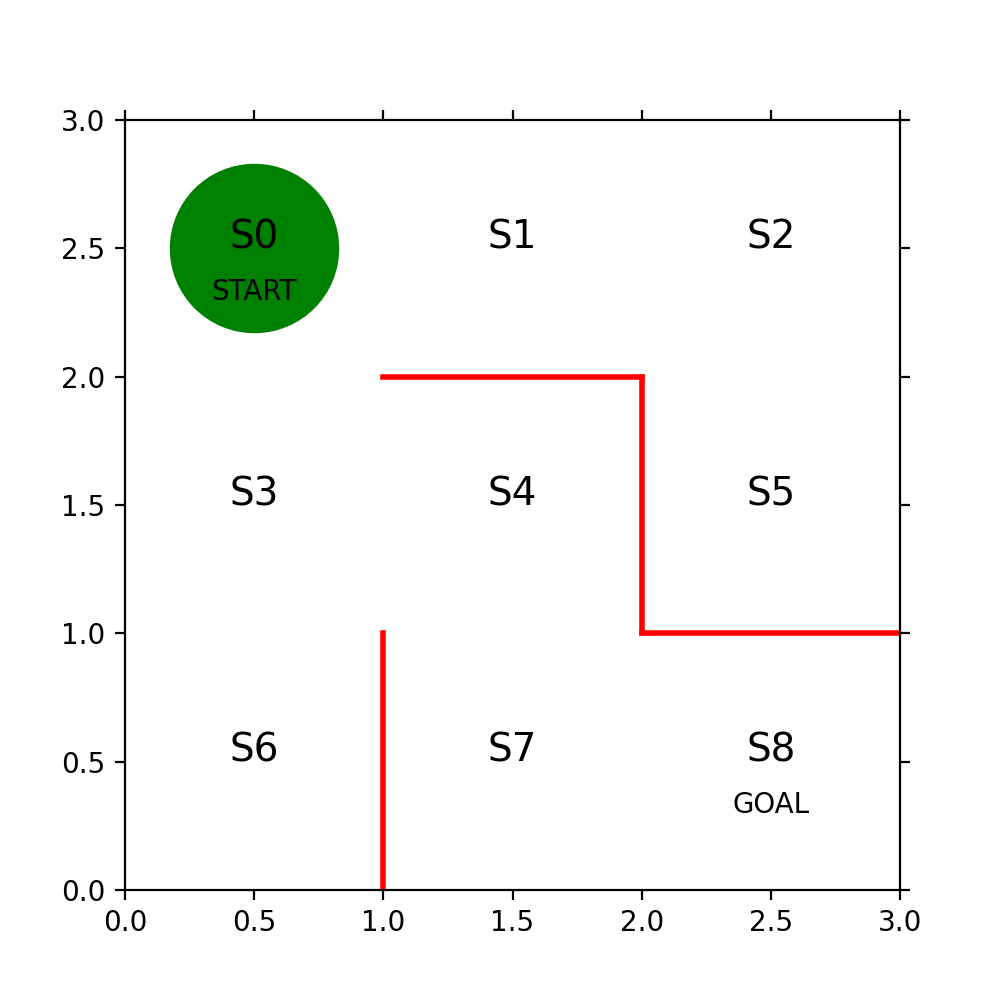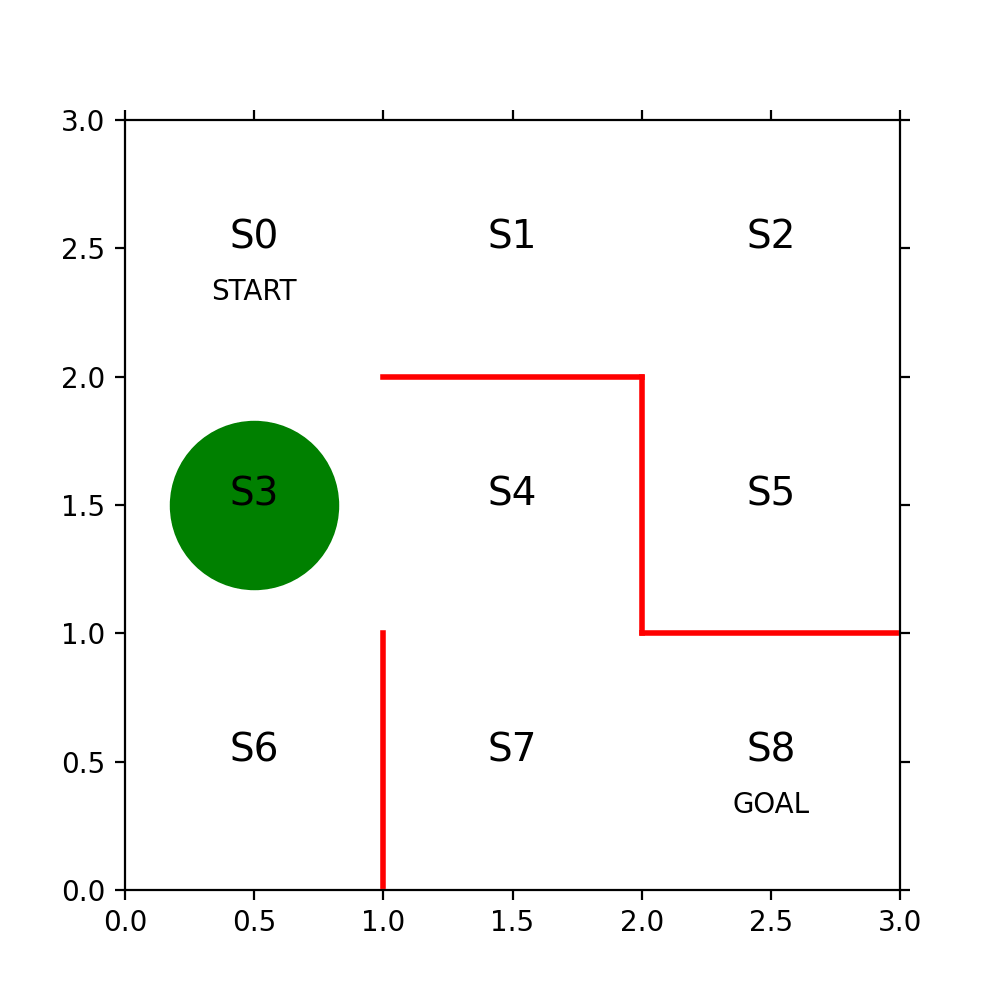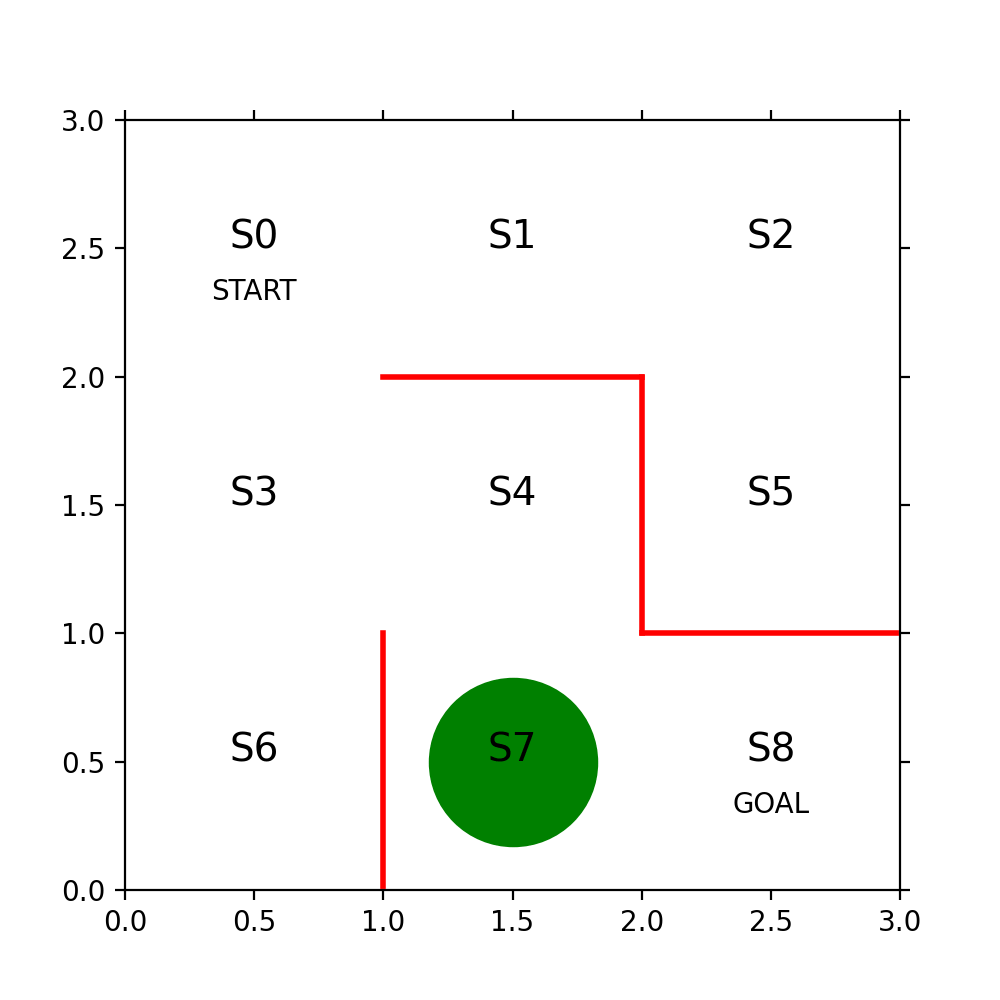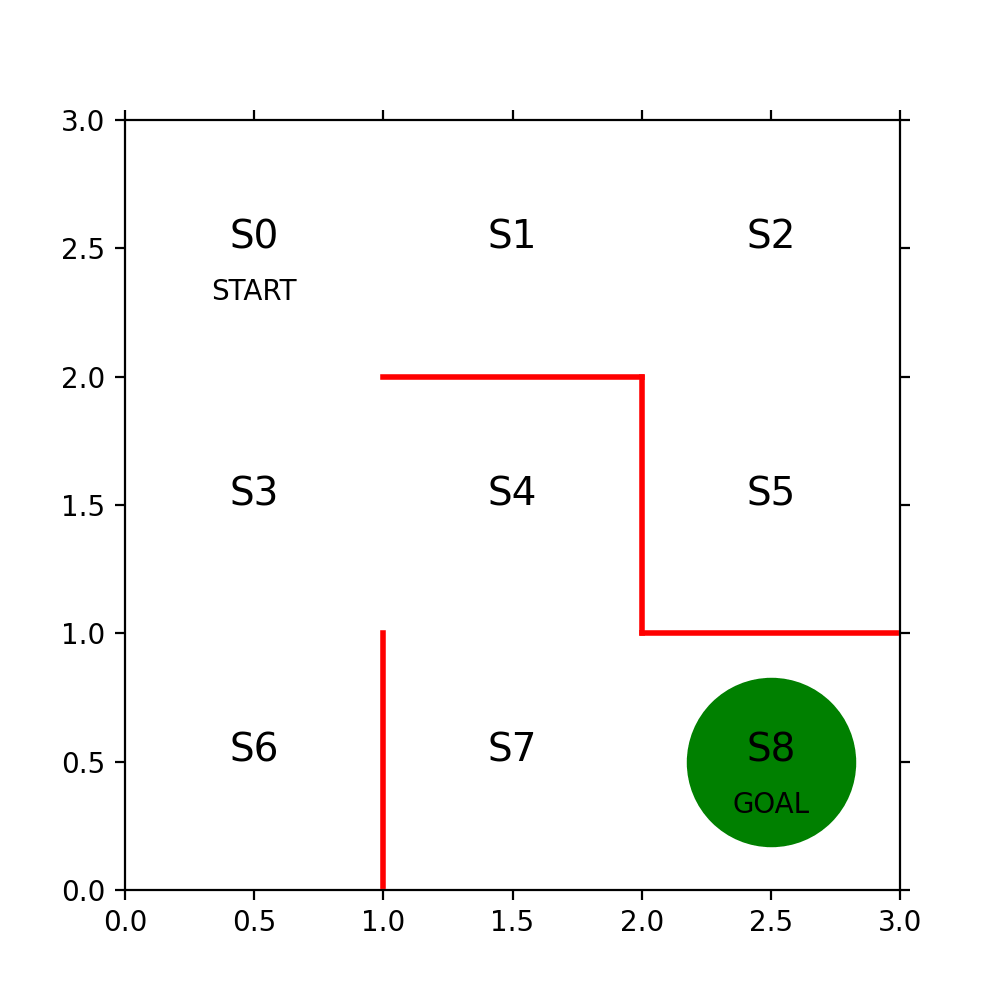
まず3x3の迷路を方策勾配法で解くコードの解読をするまで、本の文字の部分が意味不明だった。サポートページに式の正誤が掲載されている事に気が付かないと、数式も意味不明だ。
πとはテーブルの事でセルには確率が入っている。テーブルの縦軸(行)は状態(迷路の位置)で横軸(列)は行動の種別(上右下左)だ。θはSoftmaxを使ってπに変換されるものでNNのOutputの様なもの、あるいはWeightの様なものだ。誤解を招く表現が本の中ではなされていてtheta_0 = [[NAN, 1, 1,…といったコードを見て1に何か意味があるのだと間違った解釈をしてしまった。1の部分は乱数を使って決めても良いのだ。
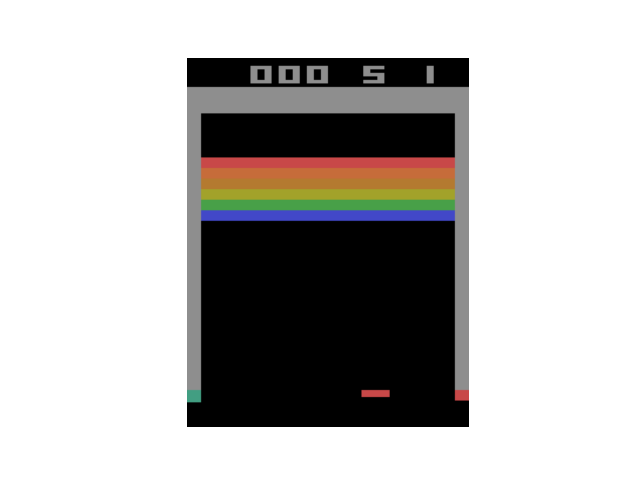
3x3の迷路問題だけでなくAtari Breakoutゲームの攻略アルゴリズムも掲載されている。Laptopで11.5hrで学習完了しAWS GPUインスタンスを使うと3hrだったと紹介されている。Laptopは16GBメモリ、core i7 7500@2.7GHz GPU無しモデルでAWSはオハイオリージョンを使い0.9ドル/hrのコストで走らせている(原稿執筆当時)。pp. 224 - 225
強化学習の歴史は古く、学習するネズミ(Skinnerの実験)の様子から機械も学習可能だとの連想に繋がって行った様だ。
補足:
オリジナルのソースはIPython環境での実行を想定している。次のようなコードはTerminal環境では動作しない。
def animate(i):
'''フレームごとの描画内容'''
state = state_history[i] # 現在の場所を描く
x = (state % 3) + 0.5 # 状態のx座標は、3で割った余り+0.5
y = 2.5 - int(state / 3) # y座標は3で割った商を2.5から引く
line.set_data(x, y)
return (line,)
# 初期化関数とフレームごとの描画関数を用いて動画を作成する
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=len(
state_history), interval=200, repeat=False)
HTML(anim.to_jshtml())
ソースが作成された時代(2018)以来matplotlibが改良されており2箇所の変更で動画を保存できる。不思議な事にソース中にpillowのimportが不要だ。set_dataメソッドの引数がscalarからlistへ変更しなと下記のエラーが発生する。
- line.set_data(x, y)
+ line.set_data([x], [y])
- HTML(anim.to_jshtml())
+ anim.save(filename="maze_pgrad.gif", writer="pillow")
Animations using Matplotlib — Matplotlib 3.10.8 documentation
Traceback (most recent call last):
...
File "/Users/tanaka/Documents/junk/python/test01/maze_pgrad.py", line 226, in animate
line.set_data(x, y)
~~~~~~~~~~~~~^^^^^^
File "/Users/tanaka/Documents/junk/python/test01/lib/python3.13/site-packages/matplotlib/lines.py", line 680, in set_data
self.set_xdata(x)
~~~~~~~~~~~~~~^^^
File "/Users/tanaka/Documents/junk/python/test01/lib/python3.13/site-packages/matplotlib/lines.py", line 1304, in set_xdata
raise RuntimeError('x must be a sequence')
RuntimeError: x must be a sequence
...
強化学習とは?
AIが経験から学ぶアルゴリズム。報酬をなるべく低コストで得る手法を学ぶアルゴリズム。アルゴリズムを採用すると最低コストの手法が得られる訳では無いが、少なくとも人間よりも賢いアルゴリズムである。(アルファ碁解体新書、初版 pp. 122)
e.g.
- 囲碁の盤面の次の一手は最善とは限らないが、人間が考える一手よりもベターなものが強化学習から得られる。
- 自動運転の判断は最善とは限らないが、人間の運転よりは安全。
「意義あるDRL」Deep Reinforcement Learning that Mattersのアブストラクトには世間に流布されている報告には再現性に乏しい報告があるので、再現性を担保するためのガイドラインの提案がなされている。アルゴリズムの中に乱数が採用されているので厳密な再現性は元々無いのだ。(pp. 236)
変更点
本の出版後の2022年にPython Package Gymのメンテナンスが行われなくなり、Farama Foundationが新たにGymnasium Packageのメンテを始めている。
そのため本に掲載のソースは動かなくなっている。
YutaroOgawa/Deep-Reinforcement-Learning-Book: 書籍「つくりながら学ぶ!深層強化学習」のサポートリポジトリです
GymからGymnasiumへの移行ガイドが用意されている。
Gym Migration Guide - Gymnasium Documentation
必要なPackageのInstallコマンドは
python -m pip install "gymnasium[classic-control]"
や
python -m pip install "gymnasium[atari]"
python -m pip install ale-py
であり Agentが動き回るEnvironmentを作るコードは
ENV = "ALE/Breakout-v5"
env = gym.make(ENV, render_mode="rgb_array")
や
ENV = "CartPole-v1"
env = gym.make(ENV, render_mode="rgb_array")
となってる。こういった情報は次の掲示板で拾った。Gymnasiumの公式ページでAtariゲームのENV変数の与え方を探したが今のところ発見できない。
なお、Breakoutを使った学習プログラムの出発点は次の様になる。
import numpy as np
import matplotlib.pyplot as plt
import gymnasium as gym
import ale_py
ENV = "ALE/Breakout-v5"
env = gym.make(ENV, render_mode="rgb_array")
print(env.observation_space)
print(env.action_space)
print(env.unwrapped.get_action_meanings())
observation, info = env.reset()
frame = env.render() # ← 画像はここから取る
plt.imshow(frame)
plt.axis("off")
plt.show()
env.close()